App::RunCronもしくはGitMasterData
Gotanda.pm #1
Jun 11th, 2014
Profile

- id: Songmu (ソンムー)
- Masayuki Matsuki
- http://www.songmu.jp/riji/
- https://metacpan.org/author/SONGMU
- FA宣言中(=無職)
- 趣味はCPANizeです
- 最近 Disposable DB Testing というバズワードを思いつきました
Recent Output
- Acme::BeerSushi
- App::LLEvalBot
- App::CPANGhq
- Parse::CommandLine
私とcron

- 「cron周りのベストプラクティス」
- Perl Hackers Hubなのにcronの話で9ページ
App::RunCron (runcron)
cron
- Webサービスは多くのcronに因って支えられている
- Jenkinsをcron代わりにする富豪の方もいるとは聞き及んでおります
- ところで私去年Ukigumo::ServerをCPANに上げました
- プロジェクトではJenkins使ってました
cronの現状
- 結果のレポートのコントロールが難しい
- メールが埋もれてフィルタ行き
script 2>&1 | $LOGGERとかやってもいいけど、コマンドの成否がわかりづらい> /dev/null 2>&1する人が続出- ε==== コ_
cronの難点
- スクリプトの成否を後続の処理で把握できない
- コマンド毎にいちいちエラー処理書くの大変だし、正しく書くのも難しい
やりたいこと
- コマンドの成功時・失敗時の通知を柔軟にコントロールしたい
- cronのjob成功時には IRCのログのnopasteのURLをnoticeするとかやりたい
- 失敗時はIRCに通知するだけじゃなくて、アラート飛ばすとかもやりたい
cronlog
- cronの実行処理をラップする
- 安心と信頼のkazuho ware
- 一枚岩で安定
- 成功時は出力を出さないで失敗時は出力を出す -> cronだとメールが飛ぶ
- 監視用途寄り
runcron
- アプリケーション用のバッチ処理をラップするためのラッパスクリプト
cronlogからかなりコピペなので安心してお使いいただけます
LOGGER="/usr/local/bin/fluent-agent-lite -f msg"
RUN="/home/app/project/env-exec runcron -- "
* * * * * $RUN command ... 2>&1 | $LOGGER cron.cmd - fluentd-srv
env-exec
環境変数一式設定してから、プロジェクトディレクトリにcdするラッパーシェル。
#!/bin/sh
set -e
export USER=app
export HOME=/home/$USER
cd $(dirname $0)
export PATH="extlib/bin:local/bin:/opt/perl-5.16/bin:$PATH"
export PERL5OPT="-Mlib=lib,extlib/lib/perl5,local/lib/perl5"
export PLACK_ENV=production
exec "$@"
runcron.yml
実行ディレクトリに配置して、Reporter情報を登録する。
timestamp: 1
reporter: None
error_reporter:
- +MyApp::Reporter::Alert
common_reporter:
- Fluentd
- File
- file: log/cron%Y-%m-%d.log
- +MyApp::Reporter::IRC
- cronのジョブごとに別の設定を適用したい場合は、
-cで別のYAMLを食わせることも可能。 runcron自体にも色々オプションがあるのでドキュメントを御覧ください。
レポーターの書き方
Perlだけど非常に簡単。newメソッドと$runcronオブジェクトを受け取るrunメソッドの2つが定義されていればOK。
package App::RunCron::Reporter::Stdout;
use strict;
use warnings;
use parent 'App::RunCron::Reporter';
sub run {
my ($self, $runner) = @_;
print STDOUT $runner->report;
}
- App::RunCron::Reporter::Fluentd 読むと色々分かるかも。
- 詳しくはドキュメントをご覧いただくか、直接ご質問下さい。
自分でラッパーコマンドを書く
% cat my-runcron
#!perl
use strict;
use warnings;
use App::RunCron;
my $runner = App::RunCron->new(
timestamp => 1,
command => [@ARGV],
logfile => 'tmp/log%Y-%m-%d.log',
reporter => 'Stdout',
error_reporter => [
'Stdout',
'File', {
file => 'tmp/error%Y-%m-%d.log'
},
],
);
$runner->run;
- 独自で書いたやつをfatpackして1つの実行ファイルにしたりしてるところも
完
GitDDL::Migrator
マイグレーションやスキーマのバージョン管理
- バージョンを数値にすると開発時に辛い
- 時間でも厳しい
- ブランチ間での協調が難しい
- ブランチAでは hoge tableが追加
- ブランチBでは fuga tableが追加 されて piyo.piyo カラムも追加
- ブランチを渡り歩くのが大変
GitDDL::Migrator
- Extended GitDDL
- SQL::Translator + Git
SQL::Translator (SQLFairy)

- 異なるデータ定義方法(DDL)の相互変換を実現するすごいやつ
- MySQL, Oracle, PostgreSQL, SQLite
- Excel, ER-diagram, XML, HTML, GraphViz
- 頑張り過ぎでビビる(その分お察しな部分も…)
- Perlモジュールだけどコマンドラインツールもあります
SQL::Translator::Diff
- SQL::Translatorは内部的にはSQL::Translatorオブジェクトを扱うようになっている
- オブジェクト同士を比較してDiffを出せるというさらに無茶な機能がある
- 任意の2つのDDLを比較して、差分のSQLを出力できる
- CREATE
- DROP
- ALTER TABLE
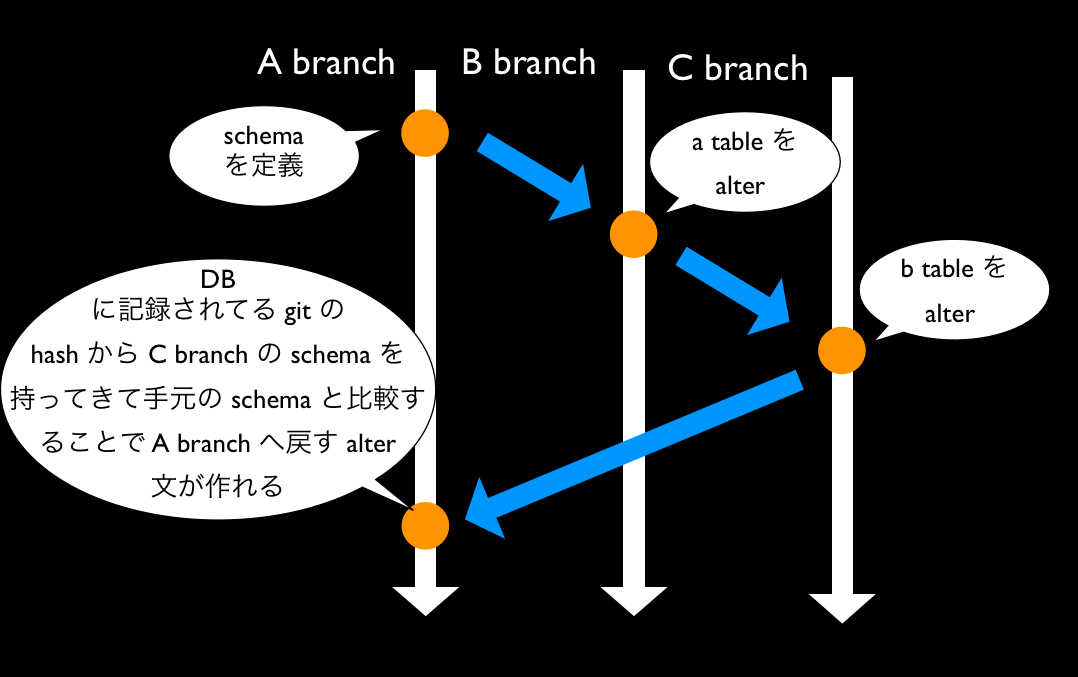
GitDDLの考え方
- sql/myapp.sqlをgitでバージョン管理する
% git log -1 sql/myapp.sqlを見てコミットハッシュを見てそれをバージョンとしてDBに保存する- その時点のSQLは
% git show {commit-hash}:sql/myapp.sqlで復元可能 - データベースに保存されているコミットハッシュ時点のSQLと現在のSQLを比較して差分SQLを算出して当て込む
バージョニングテーブル
CREATE TABLE git_ddl_version (
`version` VARCHAR(40) NOT NULL, -- commit hash
`upgraded_at` VARCHAR(20) NOT NULL UNIQUE,
`sql_text` TEXT
);
何が便利か?
- bブランチでeventテーブルが追加
- cブランチでbonusテーブルが追加
a <-> b <-> c ブランチを行き来しながら適切に差分SQLを当て込むことができる。
図
FAQ
- DBからmysqldumpしてそれとの差分をとって当て込めばいいのでは?
- mysqldumpするよりか、GitDDLの方が速くて快適
- バージョン管理してないテーブルが合ったりするかも(一部のテーブルのみGitDDLを使う)
- PartitionしてるともうSQL::Translatorは解釈できない ><
- Bug #20786 mysqldump always includes AUTO_INCREMENT http://bugs.mysql.com/bug.php?id=20786
GitDDL::Migrator
- GitDDLを運用向けに改良
- 以前のバージョンに戻すとか
- migrateの履歴を残すようにとか
- SQL::Translaterのdiffが壊れてる時用にSQL指定でバージョンあげられるようにとか
- drop & add columns じゃなくてchange columnsしたいときとか
- 特定のバージョン指定してそこに戻したいとか
- 実際のデータベースとの差分をとってDDLに不整合がないかとか
できないこと
- 複雑なDDLはParseできない
- triggerとかPartitioning入れてるやつとか
Partitioningはdailyバッチで切ってるので、その部分まではバージョン管理してない
ref. MySQL::Partition
DBIx::Schema::DSL
CREATE文をDSLで書く。
create_table user => columns {
integer 'id', pk, auto_increment;
varchar 'name';
varchar 'uid', unique;
datetime 'updated_at';
datetime 'created_at';
add_index user_created_at_idx => [qw/created_at/];
};
喜びの声
SQL::Translator::Diffが困ったDiffを出すことがあってAlter出来なくて夜もリアルで眠れない時がありましたが DBIx::Schema::DSLでスキーマ定義すればそんな変なdiffに悩まされることがなくなりました! (神奈川県 無職 34歳 男性)
マイグレーション機構とのつきあいかた
- migrate必要なときに事前にレビューはする。出力されるSQLを完全には信用しない
- 現在本番に反映されているスキーマに対して、migrateとそのロールバックがとおるかのテストを書いておく
- データ量の多いテーブルに対するAlterとかは気をつけようね
完
GitMasterData
GitMastetData
https://www.github.com/Songmu/p5-GitMasterData
- GitDDLの考え方をマスタデータ管理にも応用
- data/master_data 的なディレクトリのコミットハッシュを監視
マスタデータ管理
- データはリポジトリ管理したい
- パラメータ類をソースコード埋め込みにした場合その調整でプログラマ作業が入るのは地味にキツイのでマスターデータ化したい
マスターデータディレクトリ
% tree data/master_data
data/master_data
├── item.csv
├── sword.csv
├── monster.csv
├── stage.csv
...
実際の動き
- 前回投入した時点のコミットハッシュを覚えておく (git_master_data テーブルに保存されている)
- そのコミットハッシュ時点と現状を比較して更新のあったファイルのマスターを投入
- DELETE + BULK INSERTを1トランザクションでやる
- DBix::FixtureLoaderを内部的に使っているので、JSONやYAMLも利用可能
FAQ
- 全マスタテーブル DELETE + BULK INSERTで問題ないのでは?
- マスタテーブル量が多い場合ちょっと厭なので差分だけを当てる形にしてます
- マスタデータをアプリケーションから更新したい場合はどうするの?
- そういう場合は、item_state みたいな更新用のリレーション先をつくる形にしています
宣伝